
Most computing involves creating collection of values and then manipulating such collections. So container would be a class, where its main purpose is holding objects (its elements). Providing suitable containers for a given task and supporting them with useful fundamental operations are important steps in the construction of any application.
Those containers are implemented as class templates, which allows great flexibility in the types supported as elements. The container manages the storage space for its elements and provides member functions to access them, either directly or through iterators.
Types of containers
Sequence Containers
Sequence containers implement data structures that can be accessed sequentially:
std::array– static contiguous array,std::vector– dynamic contiguous array,std::deque– double-ended queue,std::forward_list– singly-linked list,std::list– doubly-linked list.
All standard sequence containers are so-called regular types are:
- deeply copyable: copying creates a new container object and copies all contained values,
- deeply assignable: all contained objects are copied from source to assignment target,
- deeply comparable: comparing two containers compares the contained objects,
- deep ownership: destroying the container destroys all contained objects.
Associative Containers
Associative containers implement sorted data structures that can be quickly searched (O(log n) complexity):
std::set– collection of unique keys, sorted by keys,std::map– collection of key-value pairs, sorted by keys, keys are unique,std::multiset– collection of keys, sorted by keys,std::multimap– collection of key-value pairs, sorted by keys.
Unordered Associative Containers
Unordered associative containers implement unsorted (hashed) data structures that can be quickly searched (O(1) amortized, O(n) worst-case complexity):
std::unordered_set– collection of unique keys, hashed by keys,std::unordered_map– collection of key-value pairs, hashed by keys, keys are unique,std::unordered_multiset– collection of keys, hashed by keys,std::unordered_map– collection of key-value pairs, hashed by keys.
std::vector
vector is often called the C++’s “default” dynamic array, where:
dynamic: size can be changed at runtime
array: can hold different values/objects of the same type
The elements are stored contiguously in memory.
Benefits / Drawbacks of std::vector
linear traversal/searches: fast due to cache & prefetching friendly memory layout
one-sided growth: insertion at the end in amortized constant time
potentially slow: if element type has high copy/assignment cost (reordering elements requires copying/moving them),
potentially long allocation times: very large amount of fundamental (
int, double, …) values (e.g., as host-target for GPU results) can take long time to allocate, can be mitigated by capacity reserving and in-place construction with emplace_backcapacity change: all operations that can change capacity (insert, push_back, …) may invalidate references/pointers to any vector element.
Quick Start
#include <vector>
std::vector<int> v {2, 4, 5}; // [2] [4] [5]
v.push_back(6); // [2] [4] [5] [6]
v.pop_back(); // [2] [4] [5] []
v[1] = 3; // [2] [3] [5] []
v.resize(6, 0); // [2] [3] [5] [0] [0]
std::cout << v[2]; // prints: 5
for (int x : v)
std::cout << x << ' '; // prints: 2 3 5 0 0
Creation of new vectors
// Constructs the container with the contents of the initializer list
std::vector<int> v{ 0, 1, 2, 3 }; // [0] [1] [2] [3]
// Constructs the container with count copies of elements with value value.
std::vector<int> w(4, 2); // [2] [2] [2] [2]
// Copy constructor. Constructs the container with the copy of the contents of other.
std::vector<int> b{v}; // [0] [1] [2] [3]
size vs. capacity
.size()→ number of elements in vector.resize(new_number_of_elements).capacity()→ number of available memory slots.reserve(new_capacity)
// capacity: size:
vector<int> v; // 0 0
v.push_back(7); // [7] 1 1
v.reserve(4); // [7] [] [] [] 4 1
v.push_back(8); // [7] [8] [] [] 4 2
v.push_back(9); // [7] [8] [9] [] 4 3
auto s = v.size(); // s: 3
auto c = v.capacity(); // c: 4
v.resize(6, 0); // [7] [8] [9] [0] [0] [0] 6 6
reserve before adding elements to the vector! This avoids unnecessary memory allocations and copying.Typical Memory Layout

Traversal Guidelines
- Try to only write loops if there is no well-tested library function/algorithm,
- Prefer range-based
forloops over other loop types (no bounds errors possible) - Prefer iterators over indices (no signed/unsigned integer problems, better long-term robustness)
- Avoid random access patterns; prefer linear traversals (more cache & prefetching friendly)
Shrink The Capacity / Free Memory
It is a non-binding request to reduce capacity() to size(). It depends on the implementation whether the request is fulfilled. So there are situations, where this method won’t work, thus it won’t free memory!
// capacity: size:
std::vector<int> v; // 0 0
v.resize(100); // 100 100
v.resize(50); // 100 50
v.shrink_to_fit(); // 50 50
v.clear(); // 50 0
v.shrink_to_fit(); // 0 0
for (int i = 1000; i < 1300; ++i)
v.push_back(i); // 512 300
v.shrink_to_fit(); // 300 300
std::array
std::array is a container that encapsulates fixed size arrays. The struct combines the performance and accessibility of a C-style array with the benefits of a standard container, such as knowing its own size, supporting assignment, random access iterators, etc.
Benefits / Drawbacks of std::array
linear traversal/searches: fast due to cache & prefetching friendly memory layout
size has to be a constant expression (= known at compile time)no size-changing operations: resize, insert, erase, …
Quick Start
#include <array> // for array, at()
#include <tuple> // for get()
std::array<int, 6> a{ 4, 8, 15, 16, 23, 42 };
std::cout << a[0] << ' ' << a.at(0) << ' ' << std::get<0>(a) << '\n'; // 4
std::cout << a[3] << ' ' << a.at(3) << ' ' << std::get<3>(a) << '\n'; // 16
std::cout << a.front() << '\n'; // 4
std::cout << a.back() << '\n'; // 42
std::cout << "Size: " << a.size() << '\n'; // 6
std::cout << "Max Size: " << a.max_size() << '\n'; // 6
std::cout << "Is empty: " << a.empty() << '\n'; // 0
// since C++20 -> template lambas
// since C++11 -> std::tuple_size -> can be used in compile time
auto test = []<typename TArray>(const TArray& arr){
int a[std::tuple_size<TArray>::value];
std::cout << std::size(a) << '\n';
};
test(a); // 6
std::map and std::multimap
From cppreference we can read that:
std::map is a sorted associative container that contains key-value pairs with unique keys. Keys are sorted by using the comparison function Compare. Search, removal, and insertion operations have logarithmic complexity. Maps are usually implemented as red-black trees.
std::multimap is an associative container that contains a sorted list of key-value pairs, while permitting multiple entries with the same key. Sorting is done according to the comparison function Compare, applied to the keys. Search, insertion, and removal operations have logarithmic complexity.

In other contexts, a map is known as an associative array or a dictionary. The standard-library map is a container of pairs of values optimized for lookup and insertion.
Quick Start std::map
#include <map>
std::map<int, char> m{
{9, 'a'}, {2, 'b'}, {8, 'c'} // {2:b, 8:c, 9:a}
};
m.insert({7, 'd'}); // {2:b, 7:d, 8:c, 9:a}
m.emplace(6, 'e'); // {2:b, 6:e, 7:d, 8:c, 9:a}
m[2] = 'x'; // modify {2:x, 6:e, 7:d, 8:c, 9:a}
m[3] = 'y'; // insert {2:x, 3:y, 6:e, 7:d, 8:c, 9:a}
bool foundElement = m.find(7) != std::end(m);
if (foundElement) { // true
std::cout << "Found element using find() C++11\n";
}
if (m.contains(7)) { // true
std::cout << "Found element using contains() C++20\n";
}
auto it = m.find(7); // {2:x, 3:y, 6:e, 7:d, 8:c, 9:a}, *it = 7:d
std::cout << it->first << ' ' << it->second << '\n';
if (it != end(m)) {
it = m.erase(it); // {2:x, 3:y, 6:e, 8:c, 9:a}, *it = 8:c
std::cout << it->first << ' ' << it->second << '\n';
for (auto [key, value] : map) {
std::cout << key << ": " << value << ", ";
}
std::cout << '\n';
}
std::cout << "Is empty: " << m.empty() << '\n'; // 0
std::cout << "Size: " << m.size() << '\n'; // 5
std::cout << "Count 2: " << m.count(2) << '\n'; // 1
std::set and std::multiset
From cppreference we can read that:
std::set is an associative container that contains a sorted set of unique objects of type Key. Sorting is done using the key comparison function Compare. Search, removal, and insertion operations have logarithmic complexity. Sets are usually implemented as red-black trees.
std::multiset is an associative container that contains a sorted set of objects of type Key. Unlike set, multiple keys with equivalent values are allowed. Sorting is done using the key comparison function Compare. Search, insertion, and removal operations have logarithmic complexity.
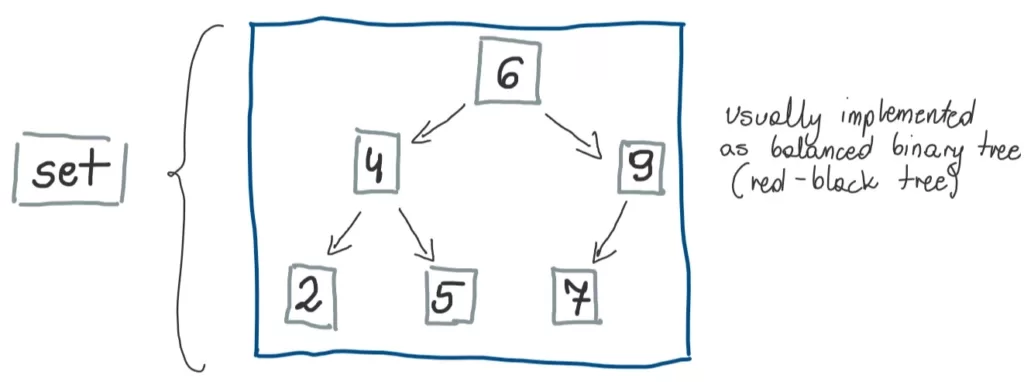
So basically, set is a map without key-value pairs, it is just keys.
Quick Start std::set
#include <set> // set
#include <algorithm> // for_each
std::set<int> s{ 9, 2, 8 }; // {2, 8, 9}
s.insert(7); // {2, 7, 8, 9}
s.erase(8); // {2, 7, 9}
for (auto elem : s) {
std::cout << elem << ' ';
}
std::cout << '\n';
std::for_each(s.begin(), s.end(), [](auto elem){
std::cout << elem << ' ';
});
std::cout << '\n';
bool foundElement = s.find(7) != std::end(s);
if (foundElement) { // true
std::cout << "Found element using find() C++11\n";
}
if (s.contains(7)) { // true
std::cout << "Found element using contains() C++20\n";
}
auto it = s.find(7); // {2, 7, 9}, *it = 7
if (it != end(s)) {
it = s.erase(it); // {2, 9}, *it = 9
}
std::cout << "Is empty: " << s.empty() << '\n'; // 0
std::cout << "Size: " << s.size() << '\n'; // 2
std::cout << "Count 2: " << s.count(2) << '\n'; // 1
Quick Start std::multiset
#include <set>
std::multiset<int> s; // empty
s.insert(8); // 8
s.insert(7); // 7 8
s.insert(2); // 2 7 8
s.insert(7); // 2 7 7 8
s.erase(7); // 2 8
Some C++ Tips for Associative Containers
How to make keys orderable
Key Comparison is based on equivalence.
if (a == b) {
std::cout << "a and b a are equal\n";
}
if (!(a < b) && !(b < a)) {
std::cout << "a and b are equivalent\n";
}
The C++ standard library uses equivalence based on less than
for ordering objects (according to a strict weak ordering).
Ordered containers take an additional type parameter:
set<Key,KeyComp>,map<Key,Mapped,KeyComp>, …
The type KeyComp needs to provide a public member function
bool operator() (Key const&, Key const&) const
which returns true, if the first argument should be ordered before the second. The default is std::less<Key>.
Change Keys Without Copying It
std::set<char> s{ 'a', 'c', 'e' };
auto na = s.extract('a');
na.value() = 'z';
s.insert(std::move(na)); // move node back in
std::map<int, std::string> m{ {2, "a"}, {3, "x"} };
auto n2 = m.extract(2);
n2.key() = 5;
m.insert(std::move(n2)); // move node back in
Transfer Key(-Value Pair) Between Sets / Maps
… without copying or moving key/value objects.
std::set<std::string> s {"a","b","e"};
std::set<std::string> t {"x","z"};
t.insert(s.extract("a"));
std::unordered_set and std::unordered_map
From cppreference:
Unordered set is an associative container that contains a set of unique objects of type Key. Search, insertion, and removal have average constant-time complexity.
Internally, the elements are not sorted in any particular order, but organized into buckets. Which bucket an element is placed into depends entirely on the hash of its value. This allows fast access to individual elements, since once a hash is computed, it refers to the exact bucket the element is placed into.
Container elements may not be modified (even by non const iterators) since modification could change an element’s hash and corrupt the container.
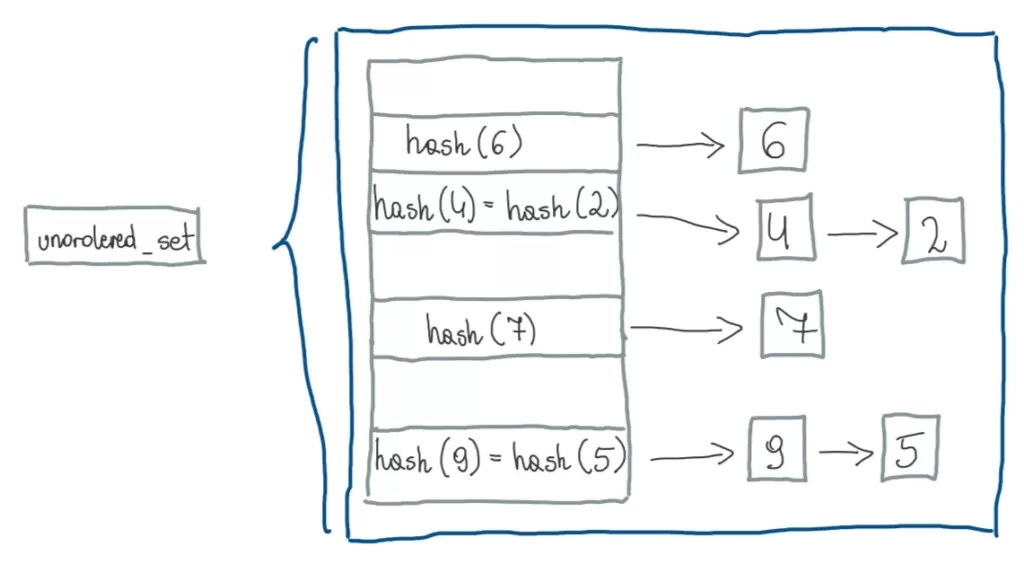
From cppreference:
Unordered map is an associative container that contains key-value pairs with unique keys. Search, insertion, and removal of elements have average constant-time complexity.
Internally, the elements are not sorted in any particular order, but organized into buckets. Which bucket an element is placed into depends entirely on the hash of its key. Keys with the same hash code appear in the same bucket. This allows fast access to individual elements, since once the hash is computed, it refers to the exact bucket the element is placed into.
Two keys are considered equivalent if the map’s key equality predicate returns true when passed those keys. If two keys are equivalent, the hash function must return the same value for both keys.
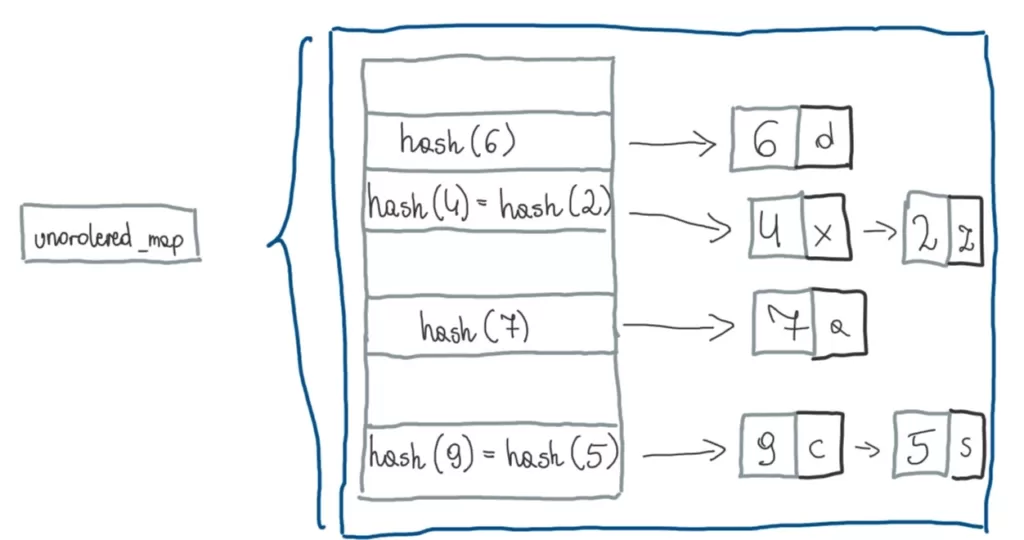
Some C++ Tips for Unordered Associative Containers
How to make keys hashable
Unordered containers take an additional type parameter:
set<Key,Hasher>,map<Key,Mapped,Hasher>, …
The type Hasher needs to provide a public member function
std::size_t operator() (Key const&) const
which returns the hash value (= an unsigned index) for a given key. The default is std::hash<Key>.
Reference:
https://stroustrup.com/Tour.html
https://www.geeksforgeeks.org/containers-cpp-stl/
https://en.cppreference.com/w/cpp/container/vector
https://hackingcpp.com/cpp/std/vector.html
https://www.geeksforgeeks.org/array-class-c/
https://en.cppreference.com/w/cpp/container/array
https://en.cppreference.com/w/cpp/container/array/tuple_size
https://hackingcpp.com/cpp/std/associative_containers.html
https://en.cppreference.com/w/cpp/container/set
https://en.cppreference.com/w/cpp/container/map
Another articles on my blog that are similar: